.png)
Working of WEP
WORKING OF WEP
The Wired Equivalent Privacy protocol is used in 802.11 networks
to protect link-level data during wireless transmission.
It is described in detail in the 802.11 standard [15];
we reproduce a brief description to enable the following discussion of its properties.
WEP relies on a secret key shared between the communicating
parties to protect the body of a transmitted frame of data.
Encryption of a frame proceeds as follows:
CHECKSUMMING:
First, we compute an integrity checksum c(M)
on the message . We concatenate the two to obtain a plaintext
P=(M,c(M)), which will be used as input to the second stage.
Note that c(M), and thus , does not depend on
the key .
c(M)=Total no. of message bits to be sent;

ENCRYPTION:
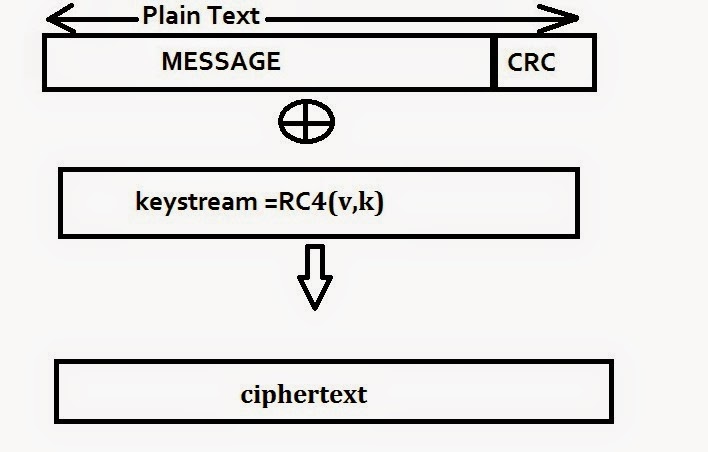 In the second stage, we encrypt the plaintext
In the second stage, we encrypt the plaintext
derived above using RC4. We choose an initialization vector
(IV) . The RC4 algorithm generates a keystream—i.e., a
long sequence of pseudorandom bytes—as a function of the
IV and the key . This keystream is denoted by RC4(v,k).
Then, we exclusive-or (XOR, denoted by ) the plaintext
with the keystream to obtain the ciphertext:
C=P(+)RC4(v,k).
TRANSMISSION:
Finally, we transmit the IV and the ciphertext over
the radio link.
Symbolically, this may be represented as follows:
A-->B:v,(P(+)RC4(v,k)) where P=(M,c(M))

We will consistently use the term message (symbolically,M) to
refer to the initial frame of data to be protected, the term plaintext
(P) to refer to the concatenation of message and checksum as it is
presented to the RC4 encryption algorithm, and the term ciphertext
(C) to refer to the encryption of the plaintext as it is transmitted
over the radio link.

To decrypt a frame protected by WEP, the recipient simply re-
verses the encryption process.
First, he regenerates the keystream RC4(v,k)
and XORs it against the ciphertext to recover the initial
plaintext:
P'=C(+)RC4(v,k)
=(P(+)RC4(v,k))(+)RC4(v,k)
=P
Next, the recipient verifies the checksum on the decrypted plaintext
P' by splitting it into the form (M',c')re-computing the checksum c(M')
and checking that it matches the received checksum c'.
This ensures that only frames with a valid checksum will be
accepted by the receiver.
The Wired Equivalent Privacy protocol is used in 802.11 networks
to protect link-level data during wireless transmission.
It is described in detail in the 802.11 standard [15];
we reproduce a brief description to enable the following discussion of its properties.
WEP relies on a secret key shared between the communicating
parties to protect the body of a transmitted frame of data.
Encryption of a frame proceeds as follows:
CHECKSUMMING:
First, we compute an integrity checksum c(M)
on the message . We concatenate the two to obtain a plaintext
P=(M,c(M)), which will be used as input to the second stage.
Note that c(M), and thus , does not depend on
the key .
c(M)=Total no. of message bits to be sent;
ENCRYPTION:
In the second stage, we encrypt the plaintext derived above using RC4. We choose an initialization vector
(IV) . The RC4 algorithm generates a keystream—i.e., a
long sequence of pseudorandom bytes—as a function of the
IV and the key . This keystream is denoted by RC4(v,k).
Then, we exclusive-or (XOR, denoted by ) the plaintext
with the keystream to obtain the ciphertext:
C=P(+)RC4(v,k).
TRANSMISSION:
Finally, we transmit the IV and the ciphertext over
the radio link.
Symbolically, this may be represented as follows:
A-->B:v,(P(+)RC4(v,k)) where P=(M,c(M))
We will consistently use the term message (symbolically,M) to
refer to the initial frame of data to be protected, the term plaintext
(P) to refer to the concatenation of message and checksum as it is
presented to the RC4 encryption algorithm, and the term ciphertext
(C) to refer to the encryption of the plaintext as it is transmitted
over the radio link.
To decrypt a frame protected by WEP, the recipient simply re-
verses the encryption process.
First, he regenerates the keystream RC4(v,k)
and XORs it against the ciphertext to recover the initial
plaintext:
P'=C(+)RC4(v,k)
=(P(+)RC4(v,k))(+)RC4(v,k)
=P
Next, the recipient verifies the checksum on the decrypted plaintext
P' by splitting it into the form (M',c')re-computing the checksum c(M')
and checking that it matches the received checksum c'.
This ensures that only frames with a valid checksum will be
accepted by the receiver.









